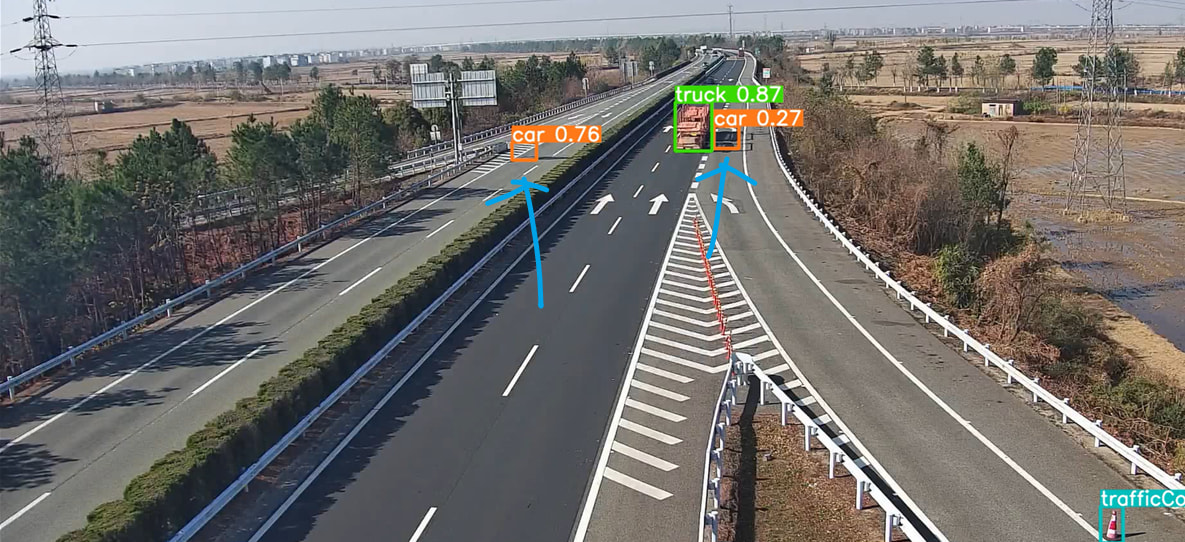
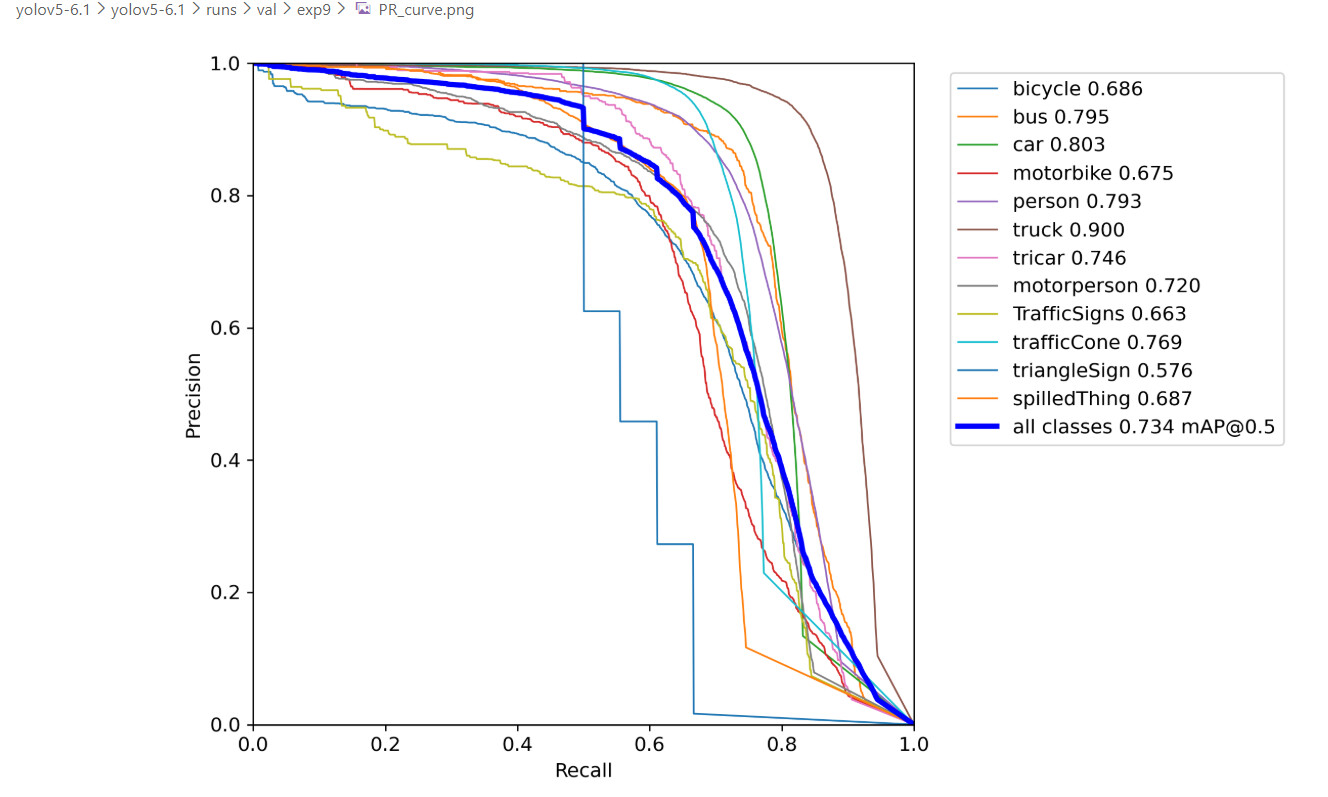
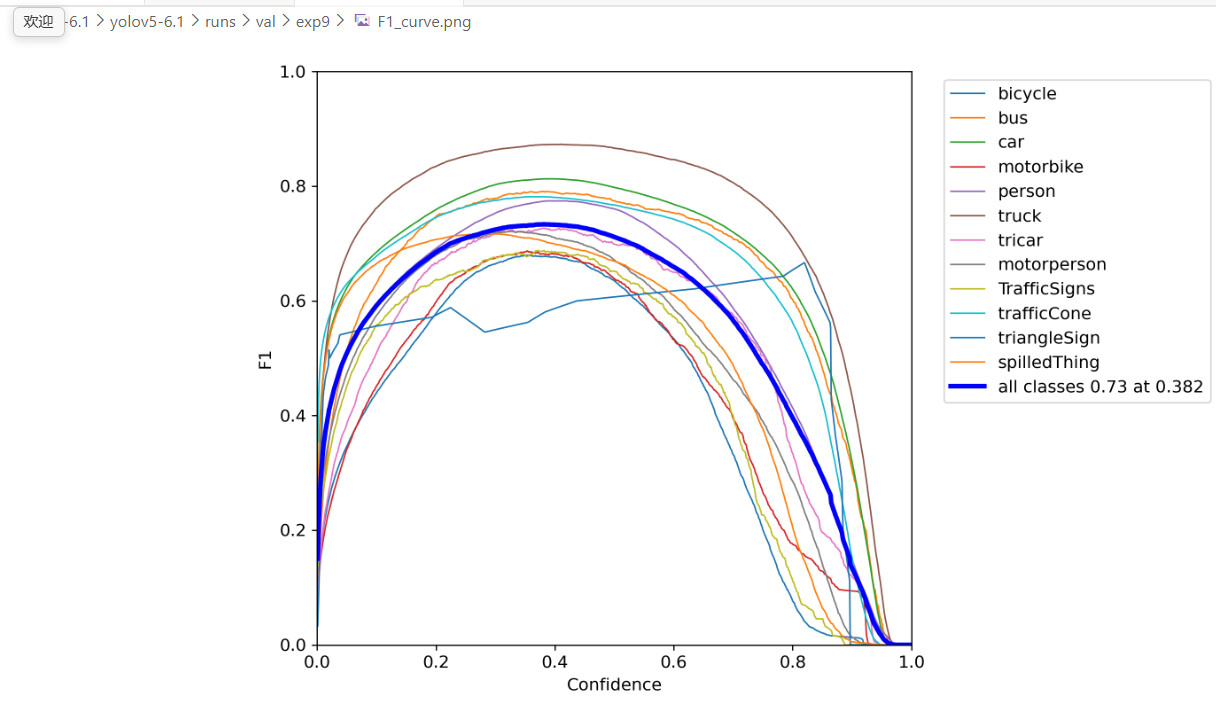
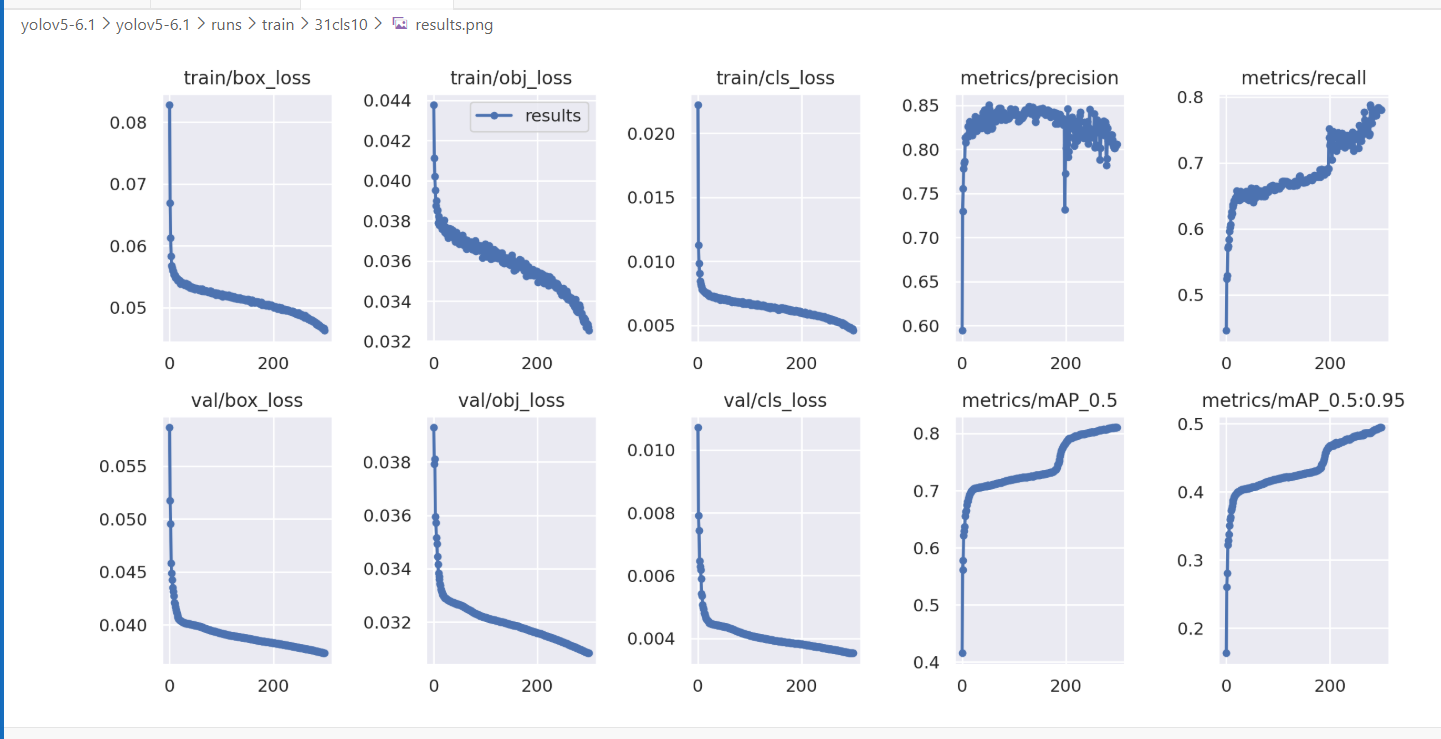
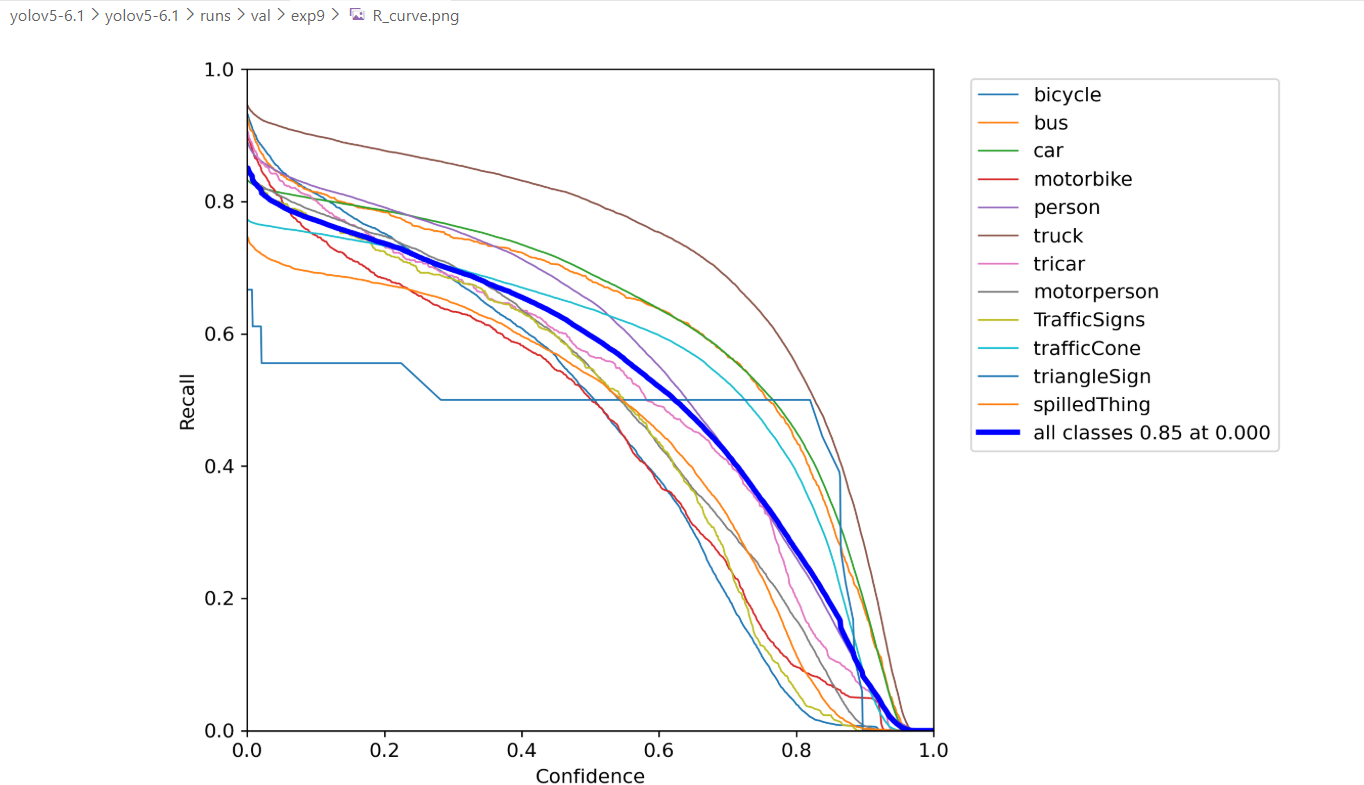
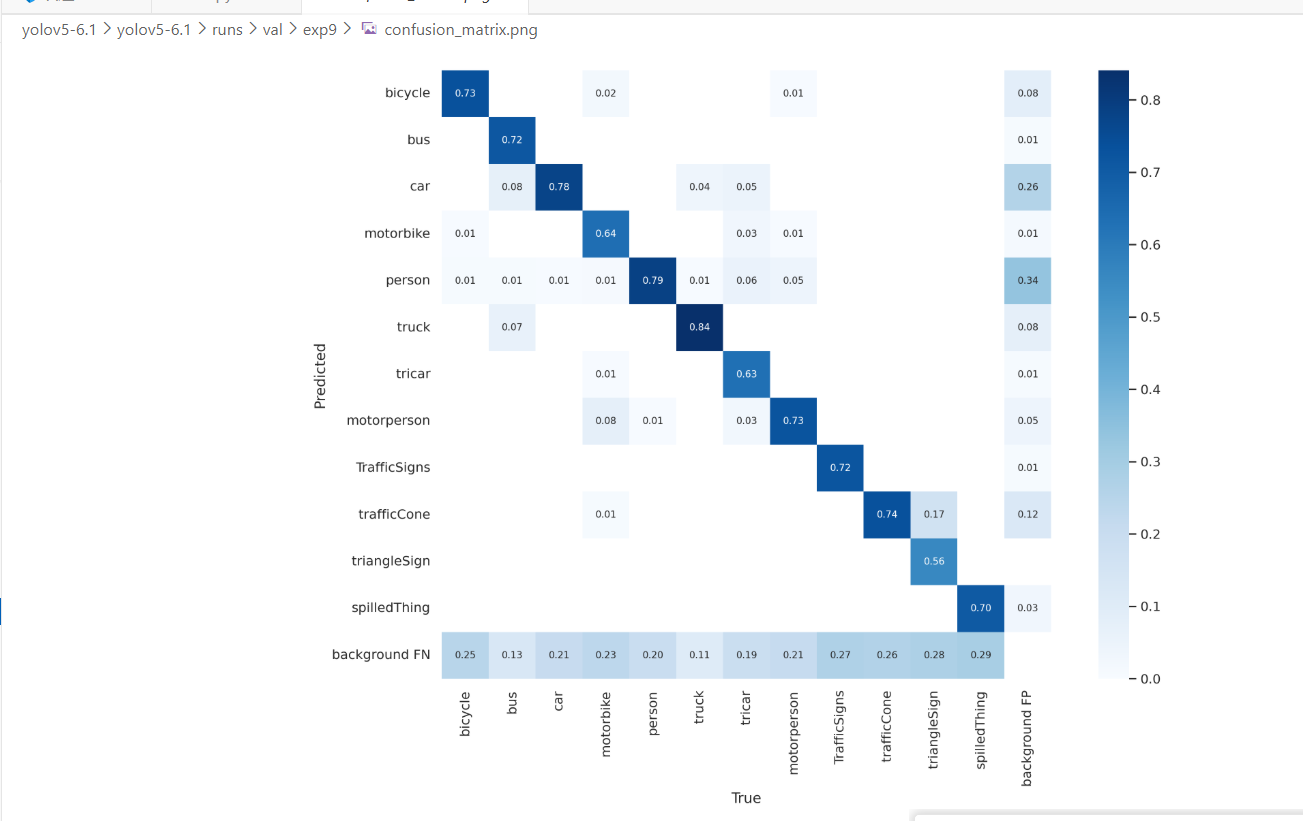
My dataset contains over 200,000 images. After training, the model achieved mAP@0.5 = 0.81 and mAP@0.5:0.95 = 0.51 with imgsz = 640, and I did not observe any false detections. However, when I switched the inference image size to imgsz = 448, the model started detecting background regions as the target, and the false positives had high confidence(0.76).
To address this, I tried a simple sample-balancing approach: extracting additional frames from videos, converting them into images, and adding them to the training set. This helped temporarily, but the issue still occurs when the model is applied to new scenes.
Using the same dataset, I tested both YOLOv5 and YOLOv8 with official/default settings: pretrained weights, batch size 256, 4× RTX 4090 (24GB), 300 epochs, and no other parameter changes.
Has anyone encountered a similar issue?