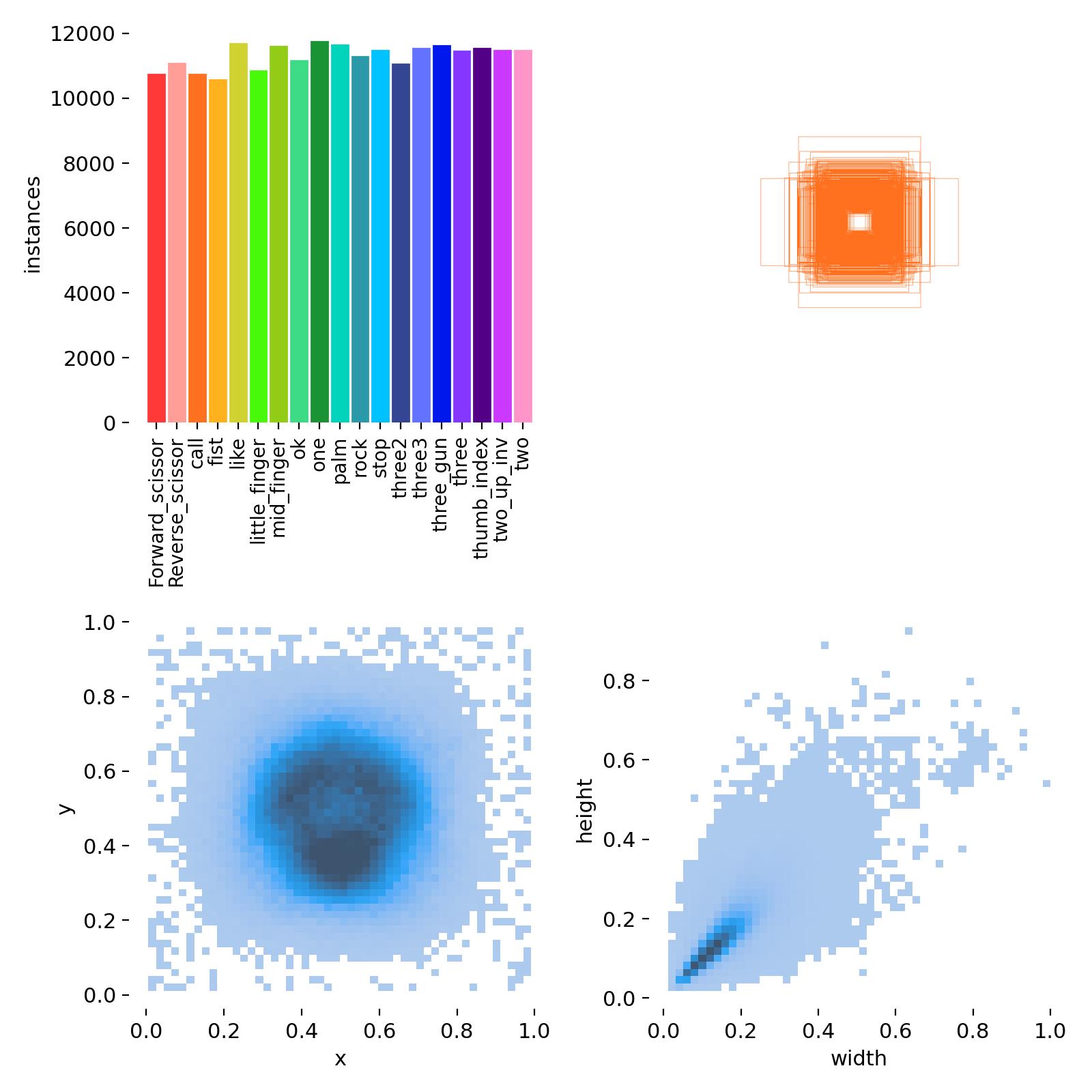
Hello everyone, I’d like to ask a question and hope to receive your help. Thank you all in advance. When recognizing the scissors gesture, I had 50,000 samples and obtained a dataset of 150,000 samples by rotating ±90°. I first trained this dataset of 150,000 (with no background images and completely correct annotations) for 100 rounds. After the training is completed, the model will misrecognize other gestures. For example, it will misrecognize the ok gesture, palm gesture, fist gesture, and gesture with only two or three fingers extended.
My first solution is:
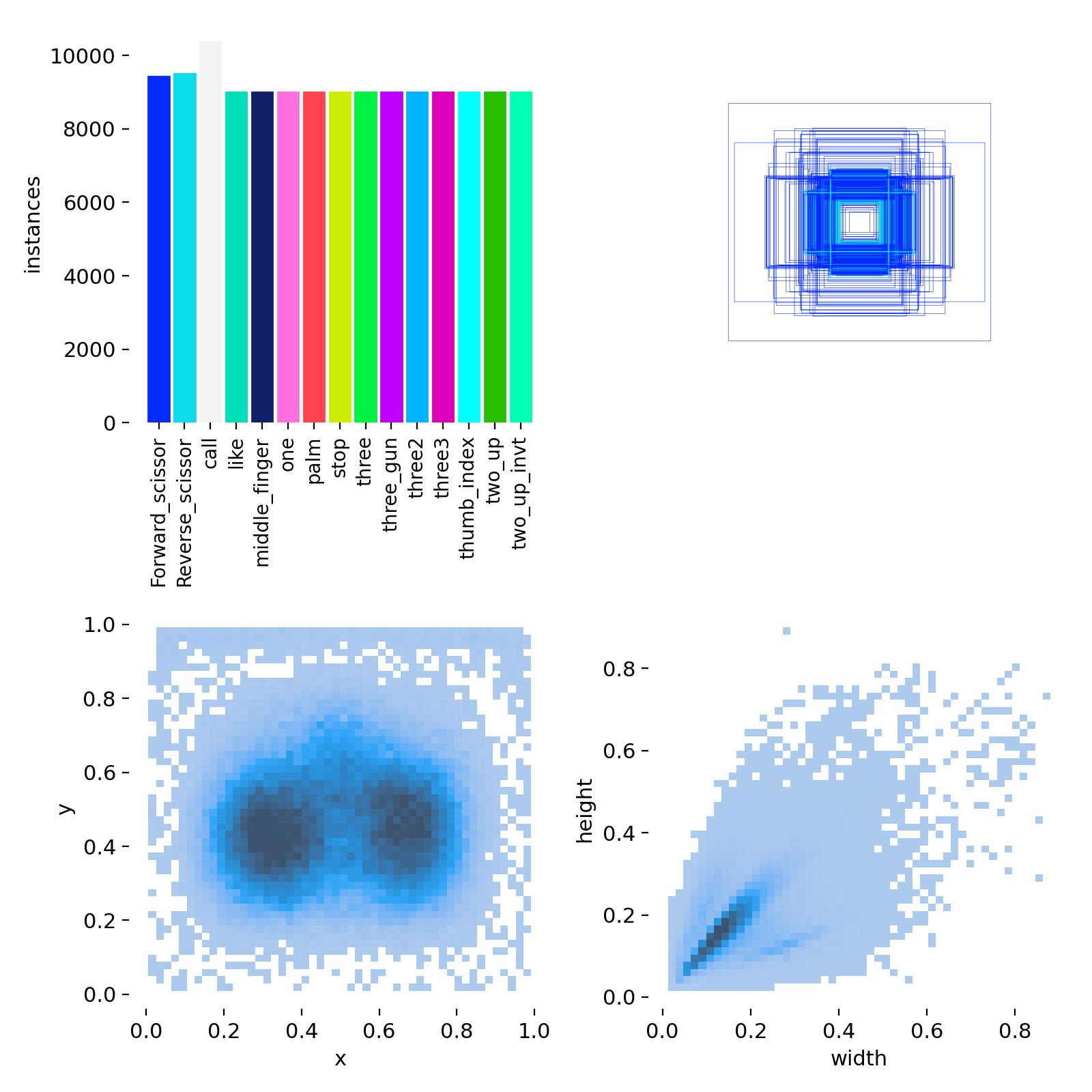
Based on the last.pt model trained in these 100 rounds, after adding 10k misidentified images as background images to the dataset, the misrecognition was significantly reduced. However, the model still misrecognizes some images that look like scissors gestures. Moreover, at long distances, as long as there are gestures, regardless of whether they are scissors gestures or not, it will recognize them. At first, I intended to add the misrecognition of these long-distance targets as background images. However, I considered that as the amount of background image data added increased, the positive recognition effect would deteriorate (because I had tried before that when more than 20,000 images were added, the positive recognition was very poor).
Later, I tried to change my thinking, so there was the second way
My second solution is:
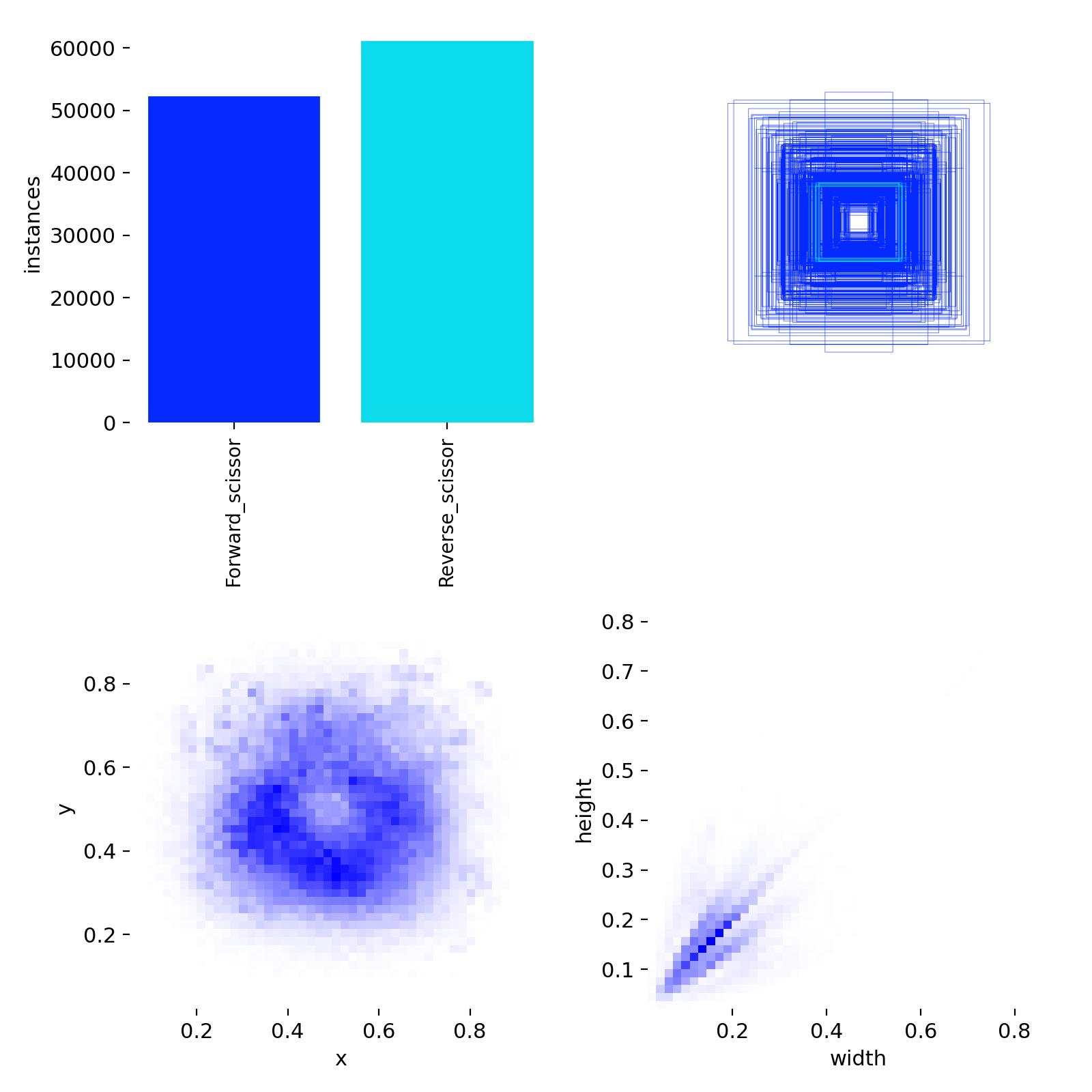
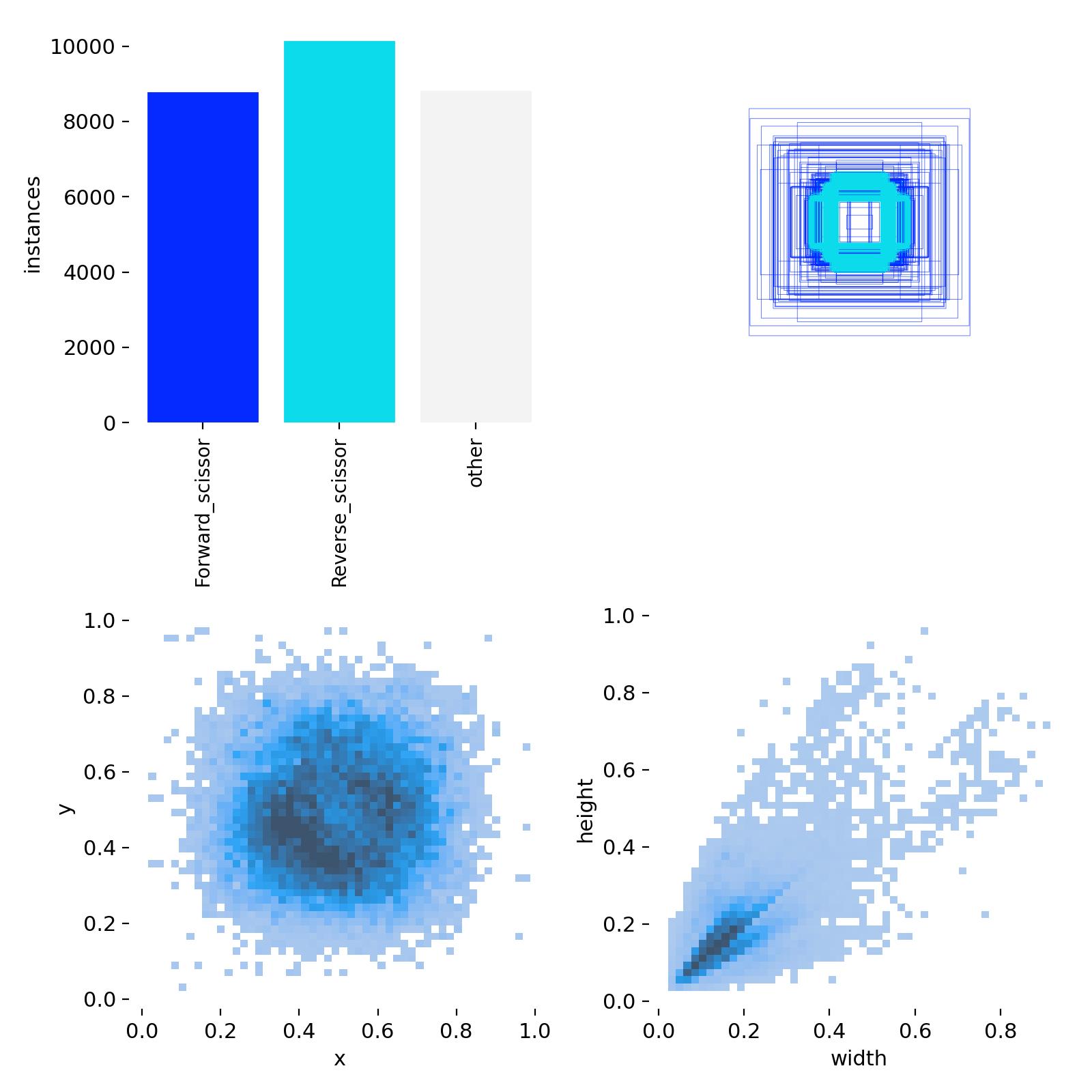
I marked all the misidentified gestures and labeled them as “other”. Among them, the scissors gestures are also divided more meticulously. The label of the scissors gesture on the back of the hand is “Reverse_scissor”, and the label of the gesture on the front of the palm is “Forward_scissor”. The sample quantities of them are respectively: other: 90,000 pieces, Forward_scissor: 60,000 copies, Reverse_scissor: 50,000 copies. However, after 100 rounds of training and using the model for reasoning, I found that the model was a little overfitted to “other”. Because I found that sometimes when I raised the scissors gesture, it was also recognized as the “other” category. I suspect it’s due to the sample size. I have now reduced the sample size to around 50,000 and started training for 200 rounds. I’m very worried that the effect of this training will also be very poor. So I sincerely hope to receive your suggestions.
I also checked the official documentation of ultralytics and the issues of ultralytics. The links are as follows: box, cls, and dfl loss gain · Issue #10375 · ultralytics/ultralytics · GitHub, inside documentation about in parameter CLS and box, whether I can set the CLS makes the model more attention classification? Issue the 如何设置多目标检测类别损失权重解决数据集分布不均衡的问题 · Issue #15615 · ultralytics/ultralytics · GitHub mentioned can set parameters in the YAML, but I don’t know how to set up. I’m extremely eager to know how to reduce the misrecognition of other gestures now. I’ve been troubled by this for several days. If any friends see this post, please kindly help me. Thank you very much!
The following is the configuration during my training and the configuration of my dataset
Training configuration
from ultralytics import YOLO
import time
if name == ‘main’:
model = YOLO(“yolov8n.pt”)
model.train(
data=r"E:\Project_Gesture\model_script\scissors.yaml",
imgsz=640,
device=0,
Lr0 = 0.01,
epochs=200,
batch=64,
close_mosaic=10,
name=“3clss_sciss_yolo8n”,
Fliplr = 0.5,
Flipud = 0.5,
degrees=15,
mosaic=0.5
mixup=0.3
plots=True,
Scale = 0.5,
)
Configuration of the yaml file of the dataset:
train: [E:\All_Data\Gesture_Data\train.txt]
val: [E:\All_Data\Gesture_Data\val.txt]
cls class_weights class_weights: [0.67, 1.0, 1.2]
nc: 3
names: [‘Forward_scissor’, ‘Reverse_scissor’,‘other’]